如何以并发方式在同一个流上执行多种操作
最近看了《Java8实战》,了解了Java8 Stream的一些内容。在Java 8中,流的一个局限性在于,只能遍历一次,再次遍历的时候会出现异常:
java.lang.IllegalStateException: stream has already been operated upon or closed
对于这种情况,《Java8实战》附录C给出了一种实现方式,通过 Spliterator 结合 BlockingQueues 和 Futures 来实现这个功能。
��主要思想
首先创建一个StreamForker类对当前需要被Fork的Stream进行包装,向StreamForker类中添加的操作由索引来标识,之后可以通过索引来取到该操作的结果。
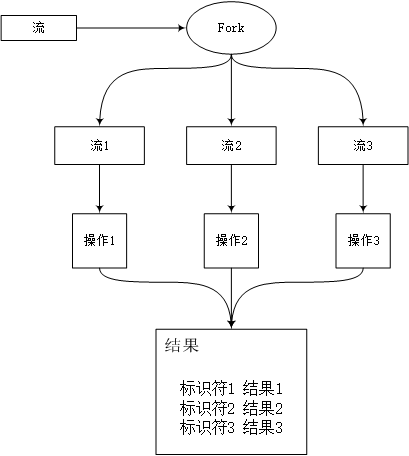
StreamForker会遍历每个操作,并创建相应的副本,并行的在复制流上执行这些操作,并将最终的结果整合到一个Map中。 Results 结果定义如下,可以用来获取执行操作的结果。
public interface Results {
public <R> R get(Object key);
}
下面,说明一下各个部分的实现。
复制流
当我们向StreamForker中添加了N个操作之后,就需要将Stream复制N份,复制N份的操作由 ForkingStreamConsumer 完成。
import java.util.List;
import java.util.Map;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Future;
import java.util.function.Consumer;
public class ForkingStreamConsumer<T> implements Consumer<T>, Results {
static final Object END_OF_STREAM = new Object();
private final List<BlockingQueue<T>> queues;
private final Map<Object, Future<?>> actions;
public ForkingStreamConsumer(List<BlockingQueue<T>> queues, Map<Object, Future<?>> actions) {
this.queues = queues;
this.actions = actions;
}
@Override
public void accept(T t) {
queues.forEach(q -> q.add(t));
}
public void finish() {
accept((T) END_OF_STREAM);
}
@Override
public <R> R get(Object key) {
try {
return ((Future<R>) actions.get(key)).get();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
这个类实现了Consumer接口和Reuslts接口,并持有queues和actions两个引用。
在这里,每当ForkingStreamConsumer接受流中的一个元素,它就会将该元素添加到所有队列,finish()方法会将最后一个哨兵元素添加到所有队列。
Results接口的get()方法会根据键值取到相应的Future来获取结果,解析并返回。
应用操作
ForkingStreamConsumer负责分发元素,还需要一个去处理BlockingQueue里的元素。这里使用 Spliterator 来完成这个而操作,通过 StreamSupport.stream() 和 Spliterator 的实现可以创建一个新的流。
import java.util.Spliterator;
import java.util.concurrent.BlockingQueue;
import java.util.function.Consumer;
public class BlockingQueueSpliterator<T> implements Spliterator<T> {
private final BlockingQueue<T> q;
public BlockingQueueSpliterator(BlockingQueue<T> q) {
this.q = q;
}
@Override
public boolean tryAdvance(Consumer<? super T> action) {
T t;
while (true) {
try {
t = q.take();
break;
} catch (InterruptedException e) {
}
}
if (t != ForkingStreamConsumer.END_OF_STREAM) {
action.accept(t);
return true;
}
return false;
}
@Override
public Spliterator<T> trySplit() {
return null;
}
@Override
public long estimateSize() {
return 0;
}
@Override
public int characteristics() {
return 0;
}
}
Spliterator接口有四个方法需要实现。
tryAdvance() 定义如何顺序遍历每个元素,如果还有需要遍历的元素,返回 true,否则返回 false;它从BlockingQueue中取得原始流的元素,这些元素由ForkingStreamConsumer添加,然后依次处理这些元素。直到发现哨兵元素,表示队列中没有需要处理的元素了。trySplit() 会将当前元素划分出一部分,返回一个新的Spliterator,同时这两个Spliterator会并行执行。如果无法划分则返回 null。estimateSize() 用于估算还有多少个元素需要遍历。在这里没有进行估算。characteristice() 表示该Spliterator有哪些特性,用于可以更好控制和优化Spliterator的使用。
通过实现的BlockingQueueSpliterator的延迟绑定能力,处理流中的各个元素。
框架
上面两部分都已经实现,下面需要实现一个框架,可以包装Stream,为Stream添加fork操作,并获取操作结果。
import java.util.*;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.Future;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.function.Function;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
public class StreamForker<T> {
private final Stream stream;
private final Map<Object, Function<Stream<T>, ?>> forks = new HashMap<>();
public StreamForker(Stream<T> stream) {
this.stream = stream;
}
public StreamForker<T> fork(Object key, Function<Stream<T>, ?> f) {
forks.put(key, f);
return this;
}
public Results getResults() {
ForkingStreamConsumer<T> consumer = build();
try {
stream.forEach(consumer);
} finally {
consumer.finish();
}
return consumer;
}
private ForkingStreamConsumer<T> build() {
List<BlockingQueue<T>> queues = new ArrayList<>();
Map<Object, Future<?>> actions = forks.entrySet().stream()
.reduce(new HashMap<Object, Future<?>>(),
(map, e) -> {
map.put(e.getKey(), getOperationResult(queues, e.getValue()));
return map;
}, (m1, m2) -> {
m1.putAll(m2);
return m1;
});
return new ForkingStreamConsumer<>(queues, actions);
}
private Future<?> getOperationResult(List<BlockingQueue<T>> queues, Function<Stream<T>, ?> f) {
BlockingQueue<T> queue = new LinkedBlockingDeque<>();
queues.add(queue);
Spliterator<T> spliterator = new BlockingQueueSpliterator<>(queue);
Stream<T> source = StreamSupport.stream(spliterator, false);
return CompletableFuture.supplyAsync(() -> f.apply(source));
}
}
StreamForker的构造方法接收一个流,表示需要被fork的流。通过 fork() 方法可以增加标识和操作。
getResults() 方法返回 Results 接口的实现,可以通过标识获取操作结果。通过 build() 构建一个ForkingStreamConsumer,将原始流中的元素挨个分发,最后finish()表示操作结束。
build() 方法用于构建ForkingStreamConsumer,主要创建一个Map,Map的键就是之前的各个操作的标识,值是各个操作的结果,用Futrue来表示。每个Future都是通过 getOperationResult() 创建的。
getOperationResult() 方法会创建一个新的 BlockingQueue,并将其添加到队列的列表。这个BlockingQueue用于存储分发的原始流中的元素,然后将队列绑定到BlockingQueueSpliterator上用来创建一个新的流,最后创建一个Future来执行需要在这个流上应用的操作。
使用
到此整个StreamForker就完成了,这里我们应用一下,同时求一个整数流的最大值、最小值和平均值。
import java.util.Comparator;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
Stream<Integer> stream = IntStream.rangeClosed(1, 10).boxed();
Results results = new StreamForker<Integer>(stream)
.fork("min", s -> s.min(Comparator.naturalOrder()).orElse(null))
.fork("max", s -> s.max(Comparator.naturalOrder()).orElse(null))
.fork("avg", s -> s.mapToInt(x -> x).average().orElse(0))
.getResults();
int maxVal = results.get("max");
int minVal = results.get("min");
double avgVal = results.get("avg");
System.out.println("Max Value: " + maxVal);
System.out.println("Min Value: " + minVal);
System.out.println("Avg Value: " + avgVal);
}
}
使用StreamForker,可以复制一个整数流,并在每个流上应用不同的操作。同时内部实现是异步的, getResults()方法会立即返回,只有当需要取用结果的时候才会尝试等待操作执行完成。
上面代码的输出如下:
Max Value: 10
Min Value: 1
Avg Value: 5.5
参考内容